
物理直觉不再是人类专属?LeCun等新研究揭示AI可如何涌现出此能力
物理直觉不再是人类专属?LeCun等新研究揭示AI可如何涌现出此能力在当今的 AI 领域,图灵奖得主 Yann LeCun 算是一个另类。即便眼见着自回归 LLM 的能力越来越强大,能解决的任务也越来越多,他也依然坚持自己的看法:自回归 LLM 没有光明的未来。
来自主题: AI技术研报
8745 点击 2025-02-20 16:55
 搜索
搜索
在当今的 AI 领域,图灵奖得主 Yann LeCun 算是一个另类。即便眼见着自回归 LLM 的能力越来越强大,能解决的任务也越来越多,他也依然坚持自己的看法:自回归 LLM 没有光明的未来。
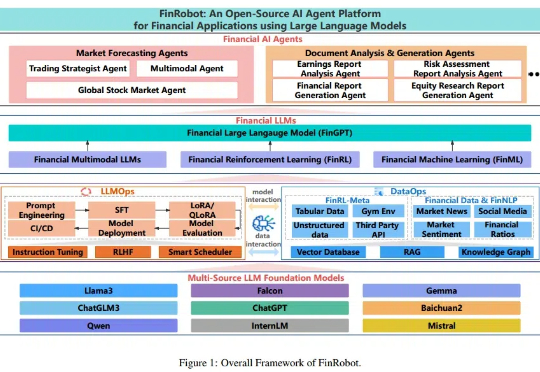
随着金融机构和专业人士越来越多地将大语言模型(LLMs)纳入其工作流程中,金融领域与人工智能社区之间依然存在显著障碍,包括专有数据和专业知识的壁垒。本文提出了 FinRobot,一种支持多个金融专业化人工智能智能体的新型开源 AI 智能体平台,每个代理均由 LLM 提供动力。
「慢思考」(Slow-Thinking),也被称为测试时扩展(Test-Time Scaling),成为提升 LLM 推理能力的新方向。近年来,OpenAI 的 o1 [4]、DeepSeek 的 R1 [5] 以及 Qwen 的 QwQ [6] 等顶尖推理大模型的发布,进一步印证了推理过程的扩展是优化 LLM 逻辑能力的有效路径。
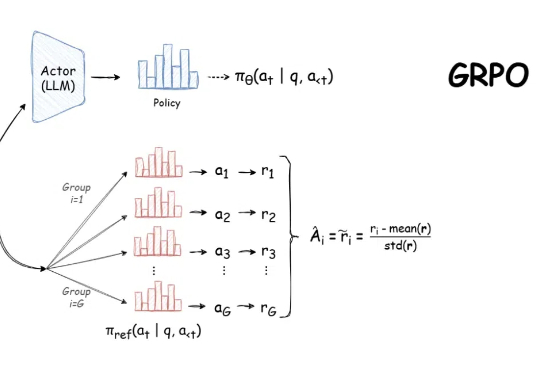
自 DeepSeek-R1 发布以来,群组相对策略优化(GRPO)因其有效性和易于训练而成为大型语言模型强化学习的热门话题。R1 论文展示了如何使用 GRPO 从遵循 LLM(DeepSeek-v3)的基本指令转变为推理模型(DeepSeek-R1)。

近日,资深机器学习研究科学家 Cameron R. Wolfe 更新了一篇超长的博客文章,详细介绍了 LLM scaling 的当前状况,并分享了他对 AI 研究未来的看法。

「除了 Claude、豆包和 Gemini 之外,知名的闭源和开源 LLM 通常表现出很高的蒸馏度。」这是中国科学院深圳先进技术研究院、北大、零一万物等机构的研究者在一篇新论文中得出的结论。

对 LLM 来说,Pre-training 的时代已经基本结束了。视频模型的 Scaling Law,瓶颈还很早。具身智能:完全具备人类泛化能力的机器人,在我们这代可能无法实现
Grok AI 最近网页版刚刚上线。我看到不少人都在比较 Grok 对标 ChatGPT 等等 LLM 大模型的研究和生成能力。我想说,背靠 X (前推特)数据库的 Grok AI,最好的使用方式难道不是实时监测全球媒体热点吗?
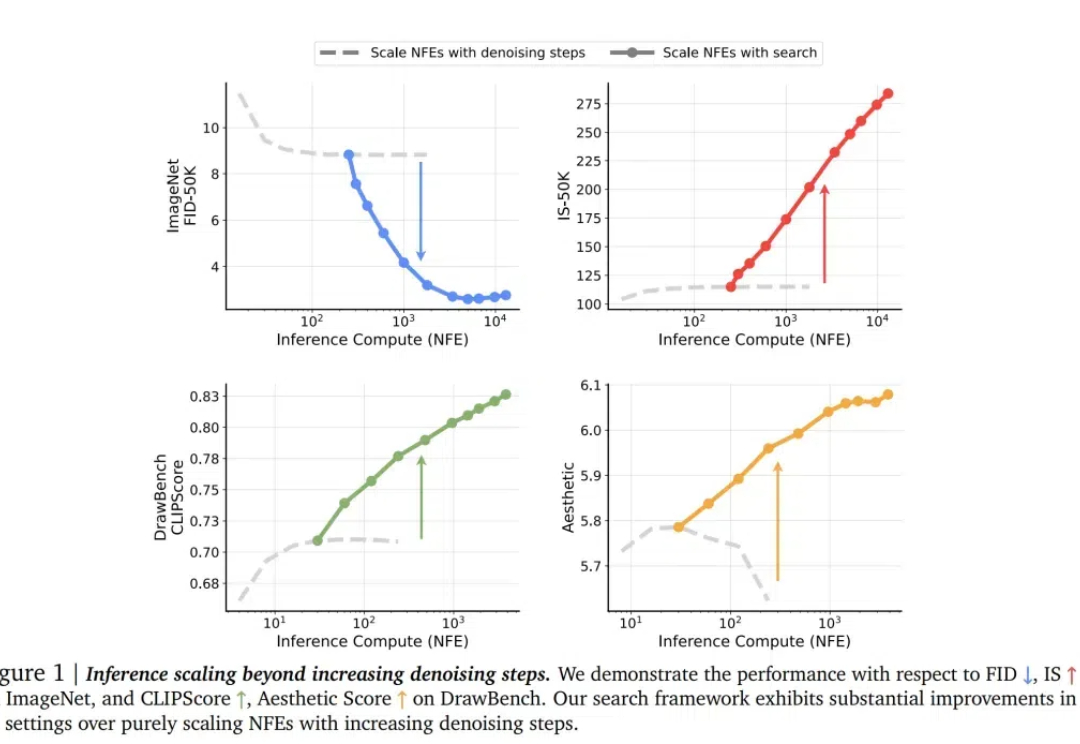
对于 LLM,推理时 scaling 是有效的!这一点已经被近期的许多推理大模型证明:o1、o3、DeepSeek R1、QwQ、Step Reasoner mini……
自适应 LLM 反映了神经科学和计算生物学中一个公认的原理,即大脑根据当前任务激活特定区域,并动态重组其功能网络以响应不断变化的任务需求。